如果要实现一个线程安全的队列有两种方式:一种是使用阻塞算法,即队列用一个锁(入队和出队用同一把锁)或两个锁(入队和出队分别用一把锁)来实现;另一种是使用非阻塞算法,即使用循环CAS的方式实现。而ConcurrentLinkedQueue是使用非阻塞的方式来实现的基于链表的线程安全队列,采用先进先出(FIFO)规则。
Node
要学习ConcurrentLinkedQueue就先从它的节点类看起,Node的源码为:
1 | private static class Node<E> { |
Node节点主要包含了两个域:一个是数据域item,另一个是next指针,用于指向下一个节点从而构成链式队列。并且都是用volatile进行修饰的,以保证内存可见性。
另外ConcurrentLinkedQueue含有这样两个成员变量:
1 | private transient volatile Node<E> head; |
默认情况下,head节点等于tail节点等于null,即数据域和next域都为空:
1 | public ConcurrentLinkedQueue() { |
几个CAS操作
1 |
|
入队列
将入队节点添加到队列的尾部
添加4个节点的快照图: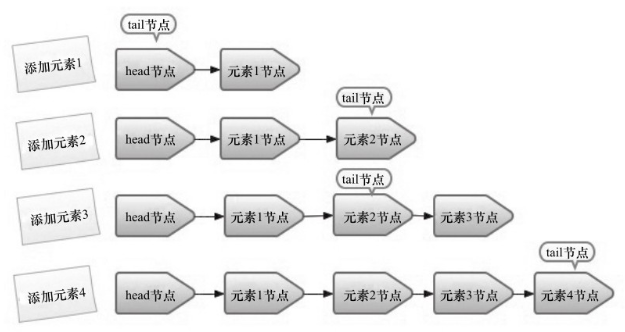
单线程入队过程
- 第一是将入队节点设置成当前队列尾结点的下一个节点,这里的尾结点不一定是tail节点,可能是tail节点的next节点
- 第二是更新tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点;如果tail节点的next节点为空,则将入队节点设置成tail节点的next节点,即tail指针不动
入队操作
1 | public boolean offer(E e) { |
HOPS的设计意图
如果让tail节点永远作为队列的尾结点,则每次都需要使用循环CAS更新tail节点,这样效率不高;因此使用hops变量来控制并减少tail节点的更新频率,当tail节点和尾结点的距离大于等于HOPS的值(默认为1)时,才更新tail节点,tail和尾结点的距离越长,使用CAS更新tail节点的次数就越少,但距离越长则每次入队时定位尾结点的时间越长,但这样仍能提高入队效率,因为通过增加对volatile变量的读操作来减少volatile变量的写操作,其写操作开销远远大于读操作的开销。
出队列
出队列的快照图: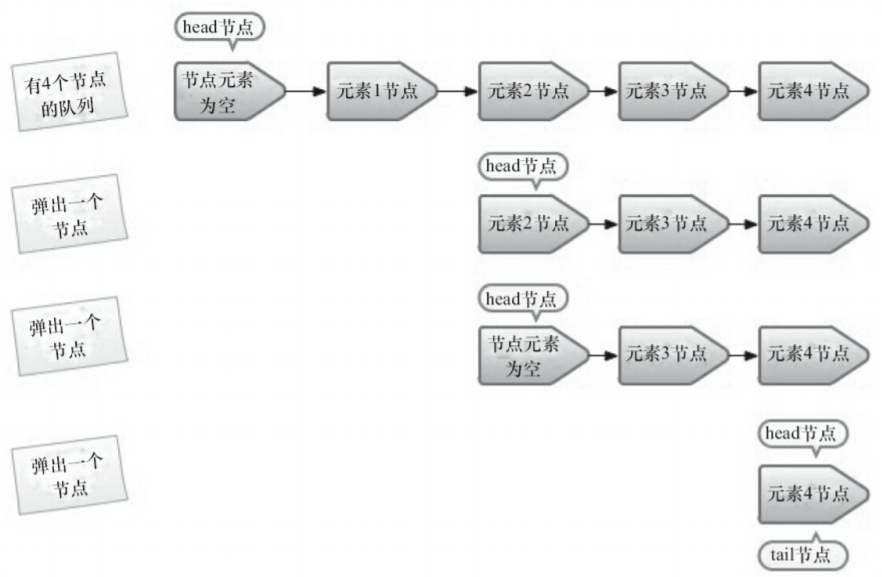
从图可知:
并不是每次出队时都更新head节点,当head节点里有元素时,直接弹出head节点里面的元素,而不会更新head节点;只有当head节点里没有元素时,出队操作才会更新head节点。其目的也是通过hops变量来减少使用CAS更新head节点的频率。
出队操作
1 | public E poll() { |
- 首先获取头结点的元素,然后判断头结点元素是否为空;
- 如果为空,表示另外一个线程已经进行了一次出队操作将该节点的元素取走;
- 如果不为空,则使用CAS将头结点的引用设置为null;
- 如果CAS成功,则直接返回头结点的元素;
- 如果不成功,表示另外一个线程已经进行了一次出队操作更新了head节点,导致元素发生变化,需要重新获取头结点。
参考来源:
- https://juejin.im/post/5aeeae756fb9a07ab11112af
- 《java并发编程的艺术》